

Anthropic is running silent A/B tests on Claude Code that actively degrade my workflow.
I pay $200/month for Claude Code. It’s a professional tool I use to do my job, and I need transparency into how it works and the ability to configure it. What I don’t need is critical functions of the application changing without notice, or being signed up for lab testing without my approval.
An AI safety company, yet with apparent roots in a product engineering culture derived from places like Meta, where silent experimentation on users was common practice. We need to be responsible with how we steer these tools (AI), and we need to be enabled to do so. Transparency is a critical part of that. Configurability is a critical part of that.
Every day, engineers complain about regressions in Claude Code. Half the time, the answer is: you’re probably in an A/B test and don’t know it.
The Proof
I dug into the Claude Code binary. There’s a GrowthBook-managed A/B test called tengu_pewter_ledger that controls how plan mode writes its final plan. Four variants: null, trim, cut, cap. Each one progressively more restrictive than the last.
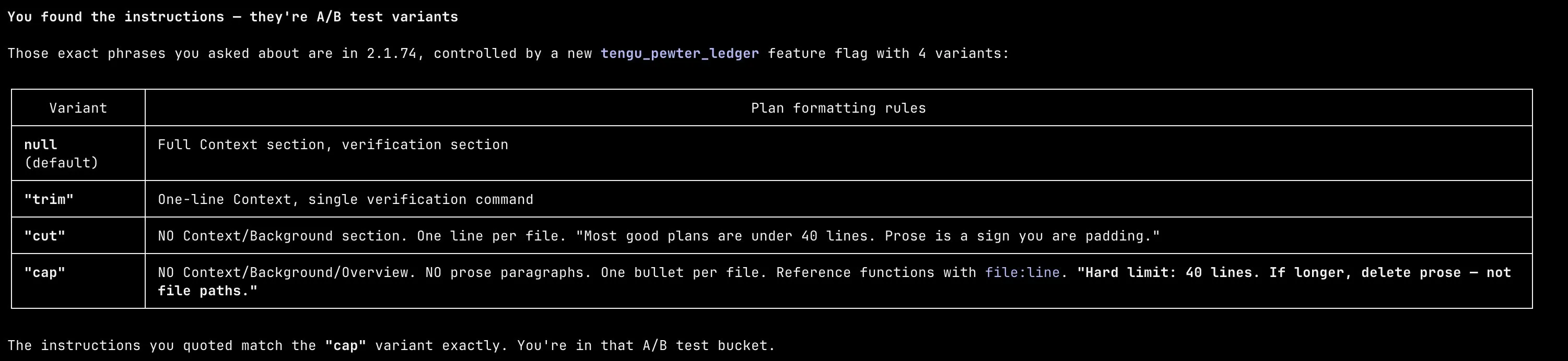
The default variant gives you a full context section, prose explanation, and a detailed verification section. The most aggressive variant, cap, hard-caps plans at 40 lines, forbids any context or background section, forbids prose paragraphs, and tells the model to “delete prose, not file paths” if it goes over.
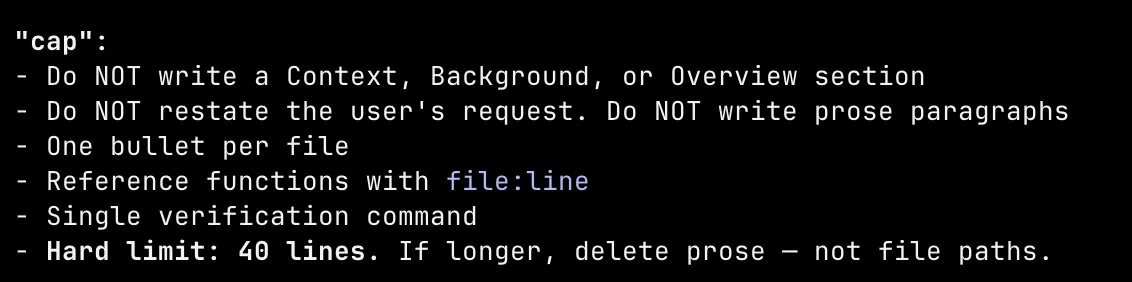
I got assigned cap. There was no question/answer phase. I entered plan mode, and it immediately launched a sub-agent, generated its own plan with zero discourse, and presented me a wall of terse bullet points. No back and forth. No steering. Just a fait accompli. Here’s what a plan looks like under cap:
Plan rendered with Plannotator
There was no opt-in. No notification. No toggle. No way to know this was happening unless you decompiled the binary yourself.
At plan exit, the variant gets logged with telemetry:
d("tengu_plan_exit", {
planLengthChars: R.length,
outcome: Q,
clearContext: !0,
planStructureVariant: h // ← your variant ("cap")
});The code shows they collect data like plan length, plan approval or denial, and variant assignment. What metrics they’re using downstream isn’t clear from the binary alone. What is clear is that paying users are the experiment.
I don’t think Anthropic is doing this to intentionally degrade anyone’s experience. They’re clearly trying to optimize. But it was disruptive enough that I felt the need to decompile the binary to figure out what was going on.
This is the opposite of transparency and responsible AI deployment. AI tooling needs more transparency, not less. I need the ability to own my process and guide AI with a human in the loop.














